Channel Partner Blog

Introduction
One of the most valuable conversations Microsoft Indirect Reseller partners can have with customers right now is not about buying more capacity by default. It is about understanding workload behaviour first. Microsoft Fabric has introduced a much more intelligent model for managing compute, and one of the most important concepts in that model is bursting. When partners understand bursting properly, they can guide customers toward better performance, lower waste, and more confident capacity decisions.
I have recently been discussing exactly this with a partner whose customer was hitting a daily peak on their purchased Fabric capacity. The pattern was consistent: for most of the day, the customer operated comfortably inside the capacity they had bought, but for roughly thirty minutes every day the workload surged hard enough to push the environment into trouble. The outcome was painful. During that peak window, the customer’s Fabric environment became unstable, workloads were throttled, and the experience felt as if the platform had suspended or shut down. From the partner’s perspective, the immediate choice seemed binary: either move the customer to a higher Fabric F SKU, or look at whether bursting could absorb the peak.
That scenario matters because it is not unusual. In fact, it is exactly the kind of real-world pattern that separates good licensing conversations from strategic advisory conversations. If the spike is brief and predictable, permanently buying a larger SKU may solve the problem technically, but it may also introduce unnecessary cost for the remaining twenty-three and a half hours of the day. Bursting changes that discussion because it allows partners to think in terms of average demand with peak protection, rather than perpetual overprovisioning.
What Microsoft Fabric Bursting Actually Means
At a practical level, bursting in Microsoft Fabric means a workload can temporarily use more compute than the purchased baseline capacity would normally suggest, allowing operations to complete faster during short spikes in demand. It is part of the broader way Fabric balances performance and reliability. Microsoft explains this together with smoothing: operations are allowed to run quickly when needed, while the consumed compute is accounted for over time rather than being treated as a single punishing spike. That is why bursting should never be described as “free extra compute.” It is better understood as temporary headroom that the platform manages intelligently.
For partners, this matters because traditional infrastructure instincts often push customers toward sizing for the absolute worst-case peak. In older environments, that was often the safest answer. In Fabric, the platform is designed to cope with short-lived bursts more gracefully. That opens the door to better commercial conversations. Instead of asking, “What is the biggest SKU we can justify right now?” the better question becomes, “What is the real operating pattern of this workload, and how often does it genuinely exceed the baseline?” That single shift in framing can save customers money and position the partner as someone who understands both the technology and the commercial model.
Example: A Daily Thirty-Minute Peak
Let’s take the scenario I was discussing with the partner and put it into plain language. The customer had purchased a Fabric capacity that was adequate for normal daytime operations. Reports ran, analytics workloads moved, and the environment behaved as expected. Then, at the same time every day, workload demand rose sharply for around thirty minutes. This could be caused by a reporting crunch, a batch ingestion cycle, a heavy warehouse operation, a Spark-driven process, or a cluster of overlapping jobs. The precise workload will differ from customer to customer, but the pattern is familiar: one short, recurring period of intense pressure.
The customer’s pain point was not that the platform was under-sized all day. The pain point was that one peak window was large enough to trigger throttling and service disruption. That distinction is vital. If a customer is under pressure all day, then the conversation is almost certainly about scaling. If a customer is stable for most of the day and only fails during a short spike, then the conversation should include bursting. Partners who fail to separate those two patterns risk recommending a permanent cost increase for what is essentially a temporary demand problem.
This is where better advisory work starts. The right thing to ask is: are we seeing sustained overload or a contained burst? If it is a contained burst, then there is a strong argument for using the platform’s built-in capabilities first, monitoring the effect, and only then deciding whether a higher F SKU is truly necessary.
Why Designing for Peak Is Often the Wrong Commercial Decision
Customers often assume that if a platform fails during a spike, then the only serious answer is to buy more capacity. That instinct is understandable, especially when business users are frustrated. But commercially, it can be the wrong move if the spike is short. Designing for peak means paying for peak all day, every day, even when the environment sits well below that level for the vast majority of its operating life.
For an indirect reseller, this creates both a risk and an opportunity. The risk is that the partner becomes seen as someone who only solves performance issues by increasing spend. The opportunity is to take a more thoughtful route: understand when the load occurs, how long it lasts, whether it is interactive or background in nature, what other workloads overlap with it, and how Fabric’s bursting and smoothing behaviour may reduce the impact. That creates a much more strategic conversation with the customer. It also demonstrates channel maturity. You are not simply reselling capacity; you are helping the customer consume cloud resources more intelligently.
In the partner case I discussed, the customer’s thirty-minute window is exactly the kind of pattern where that advisory value becomes visible. If the environment is healthy the rest of the day, then the extra cost of a larger SKU needs to be justified against one half-hour of elevated demand. Sometimes the answer will still be to scale. But it should be a data-driven decision, not a panicked reaction.
What Bursting Looks Like in Practice
The simplest way to explain this to a customer or partner is visually. The diagram below shows three things. First, the purchased baseline capacity: the level of compute the customer has effectively paid for. Second, the actual workload demand across the day, including a short but severe spike lasting about thirty minutes. Third, an illustrative view of smoothing, which helps explain how Fabric can spread the accounting impact of burst usage over time rather than forcing the entire spike to be handled as a single brute-force moment.
This visual is especially useful in conversation because it reframes the problem immediately. The issue is no longer “the customer needs more capacity all day.” The issue becomes “the customer has a daily spike that exceeds the baseline for a short period.” That is a very different problem statement, and in Microsoft Fabric, a different problem statement opens different solution options.
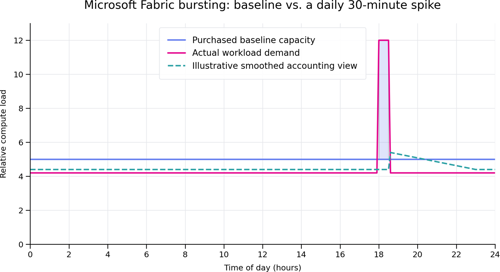
Figure 1. A conceptual view of purchased baseline capacity, a daily thirty-minute workload spike, and the idea of smoothing over time.
How to Read the Diagram in a Customer Conversation
Start with the flat line. That is the baseline: the capacity the customer has purchased through the chosen Fabric F SKU. Then look at the workload line. Most of the day it sits in a reasonable range, but during the daily peak it jumps above the baseline. That zone above the line is the problem area. Without sufficient platform protection, that is where users experience slowdowns, throttling, failures, or the feeling that the environment has effectively shut down.
Bursting allows that short-lived workload to run with temporary additional headroom so that the job can complete faster instead of being crushed by the instantaneous limit. Smoothing does not mean the work takes longer to execute. It means the accounting for consumed capacity is spread over time, which reduces the all-or-nothing effect of the spike on end-user experience. In business language, the customer gets a better shot at maintaining performance during the peak without having to permanently price that peak into the environment twenty-four hours a day.
That explanation is often enough to change the tone of the conversation. Customers stop thinking only in terms of bigger SKU equals better service. They start seeing that Fabric was built to handle exactly these patterns more intelligently.
Bursting Versus Scaling: The Decision Framework Partners Should Use
The real question is not whether scaling is good or bad. Scaling is often the right answer. The question is when it becomes the right answer. My advice to partners is simple: use a pattern-based decision framework.
If the pressure is short, predictable, and limited to a narrow time window, investigate whether bursting can absorb it. If the pressure is sustained, repeated across multiple long periods, or starts affecting large parts of the day, scale. If several concurrent workloads are all peaking together and that concurrency is becoming the norm rather than the exception, scale. If the customer’s platform is fundamentally growing and the baseline has clearly shifted upward, scale.
In other words, bursting is the smarter first conversation when the customer has a spike problem. Scaling is the smarter answer when the customer has a capacity problem. Those two things sound similar, but they are not the same. In the partner story behind this blog, the customer appears to have a spike problem first. That is why bursting deserves serious consideration before a larger SKU is treated as inevitable.
What Partners Should Do Next in a Case Like This
When a customer hits a daily peak like this, partners should resist the urge to jump straight to a commercial upsell. Instead, walk through a structured advisory motion.
First, confirm the workload pattern. Is the surge genuinely limited to about thirty minutes? Does it happen at a predictable time? Is the rest of the day stable? Second, identify what overlaps during that period. Is a report refresh colliding with warehouse ingestion? Is Spark activity lining up with interactive analytics? Third, examine whether the customer is dealing with a short-term burst or evidence of broader growth. Fourth, decide whether the immediate lever should be optimisation, workload separation, bursting, or permanent scale.
This is the type of guidance that builds trust quickly. It shows that the partner understands Fabric at an operational level and not merely a licensing level. It also gives the customer confidence that any recommendation to scale will be grounded in evidence, not assumption. Customers are usually willing to spend more when they can see that the partner first tried to protect value and efficiency.
Why This Creates a Stronger Fabric Conversation for Indirect Resellers
Microsoft Indirect Reseller partners win when they can combine technical clarity with commercial credibility. Bursting is a perfect example of that intersection. It is a technical concept, but the customer impact is commercial and experiential: lower waste, fewer unnecessary upgrades, better performance during pressure windows, and more confidence in how capacity is being used.
For a Microsoft SureStep Ambassador or any partner-led architect, this is exactly the kind of topic that strengthens long-term channel relationships. Instead of being the person who says, “you need a bigger SKU,” you become the person who says, “let’s understand the shape of your demand first, then choose the right answer.” That is a more mature discussion and, in my experience, a far more powerful one.
It also creates follow-on opportunity. Once you have helped the customer get control of daily peaks, the next conversation is about monitoring, optimisation, workload design, governance, and managed advisory services. In other words, a brief discussion about bursting can become the entry point for a much broader value proposition around Fabric success.
Final Thoughts
The end result in cases like this should never be a reflex decision. A customer with a daily thirty-minute spike may indeed end up on a higher Fabric F SKU, and that may eventually prove to be exactly the right call. But if the baseline is healthy for the rest of the day, partners owe it to the customer to evaluate bursting as part of the solution path.
That is the real lesson from the partner scenario I have been discussing. The customer did not necessarily buy the wrong platform. The customer encountered a very normal cloud reality: average demand and peak demand are not the same thing. Microsoft Fabric’s bursting model gives partners a better way to handle that reality.
So the next time a customer says, “our Fabric environment falls over for thirty minutes every day,” do not start with the biggest SKU on the price list. Start with the workload pattern. Ask what is peaking, when, for how long, and why. Then decide whether the answer is optimisation, bursting, scaling, or a combination of all three. That is how you move from being a reseller to being a trusted advisor.
Reach out to us at channel@4sight.cloud to discuss your specific scenario in detail.